RAL-Bench
Overview
We introduce RAL-Bench to quantitatively evaluate the ability of LLMs to perform application-level code generation. RAL-Bench comprises over 450 functional and non-functional evaluation points derived from 38 real projects and covers seven distinct real-world usage scenarios (e.g., Data and Security). These projects are sourced from actively maintained GitHub repositories with an average popularity of more than 1,000 stars, ensuring that they are widely used and vetted by the open-source community. Each project provides clearly specified functional requirements and measurable non-functional quality attributes (e.g., efficiency and security). Moreover, none of the projects are drawn from existing code generation benchmarks or public evaluation suites, which helps mitigate potential benchmark contamination and data leakage for LLMs. RAL-Bench is iteratively reviewed to minimize requirement ambiguity and to ensure that all manually designed test cases are precise, suitable, and executable for rigorous evaluation.
Benchmark Construction
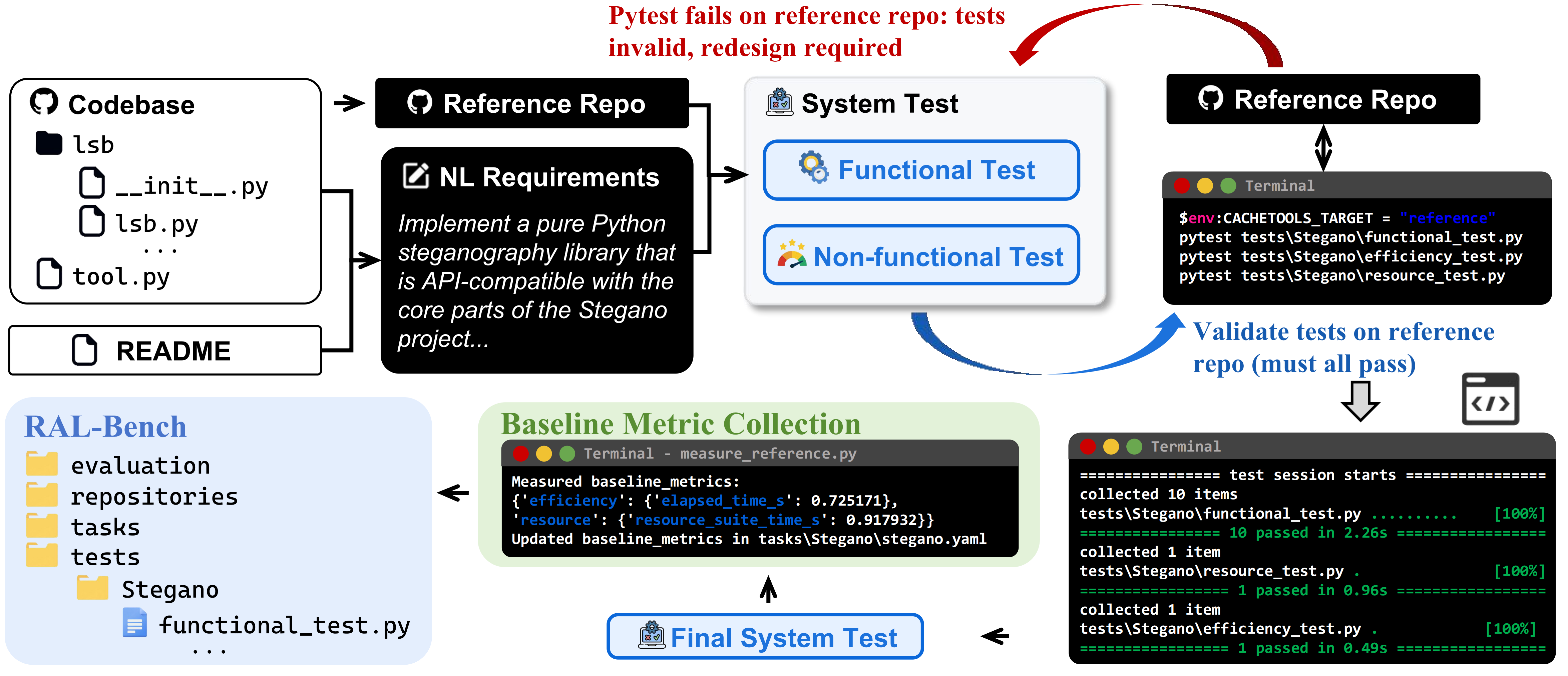
We develop an executable benchmark construction pipeline to curate real-world tasks, derive natural-language requirements, build executable system test suites, and evaluate generated repositories at scale, as shown in Figure 1.
Reference Repository Selection. We begin by selecting well-established GitHub projects as reference repositories, each with clearly documented functionality and active real-world use. For every chosen project, we pin a specific commit and snapshot its codebase within our evaluation framework. We treat this pinned snapshot as the ground-truth implementation because it is a stable, widely adopted application-level project.
Natural-Language Requirement Distillation. Given a reference repository, we distill a natural-language requirement description (NL requirement) from its README and source code. First, we synthesize a concise requirement description that summarizes the project’s core intent. Second, we deliberately phrase the requirement to mirror how developers articulate intent in practice. It takes the form of a single, highly compressed request, such as implement a pure Python steganography library. Third, the requirement specifies what the application should do and how it is expected to be used. However, it intentionally avoids prescribing a concrete project layout or implementation strategy. Under this setting, LLMs must expand a terse intent into a fully structured, executable project and infer the architecture, dependencies, and non-functional considerations without further guidance.
System Test Generation. Next, we construct system test suites for each task, consisting of black-box functional tests and non-functional tests (e.g., efficiency and security). Functional tests aim to exercise diverse functional requirements derived from real-world projects. Non-functional tests assess key non-functional quality attributes via static analysis and controlled runtime checks. Each candidate test case is first executed against the corresponding reference repository. If a test fails on the reference implementation, we deem it invalid and discard it. We retain only test cases that pass on the reference repository. This filtering ensures a sound test oracle and guarantees that the suite can be executed end-to-end in a fully automated pipeline.
Baseline Metric Collection. We run the non-functional test suite on the reference repository to collect baseline metrics for each task. These statistics are stored alongside the task configuration and later used when evaluating generated repositories. This enables fair and consistent comparisons across models and tasks.
Metric Design
We evaluate application-level code generation using two complementary metrics: functional correctness and non-functional quality attributes.
Functional correctness. The functional score of functional correctness is defined as the functional test pass rate, computed as the number of passed tests divided by the total number of tests for each task.
Non-functional quality attributes. Following the ISO/IEC 25010 quality model, we additionally assess five non-functional dimensions that are critical in practice: maintainability, security, robustness, efficiency, and resource usage.
(1) Maintainability. Maintainability is measured by the lower-bound Maintainability Index (MI) from static analysis. We operationalize maintainability using MI as a static proxy for structural complexity. Higher MI generally reflects lower structural complexity and therefore improved maintainability. Let g and b denote the MI lower bounds of the generated code and the reference implementation, respectively. To avoid hard saturation when directly using g/b, we apply a smooth compression function:
(2) Security. Security is quantified by the number of high-risk issues reported by static security analysis. Let g and b denote the number of high-risk findings in the generated code and the reference implementation, respectively. We compute a reference-aligned inverse ratio with smoothing:
(3) Robustness. Robustness is evaluated using a dedicated robustness test suite targeting invalid, boundary, and unexpected inputs. Let passed and total denote the number of passed tests and the total number of robustness tests. The robustness score is defined as:
(4) Efficiency. Efficiency is measured from the runtime statistics of the efficiency suite, using the elapsed execution time reported by the suite. Let Tgen and Tref denote the efficiency-suite execution times of the generated code and the reference implementation, respectively. If the efficiency suite fails to execute successfully (e.g., failed tests), we set E = 0; otherwise:
(5) Resource usage.
Resource usage is measured using a dedicated resource suite.
During execution, we sample resident set size (RSS) memory usage and CPU utilization of the pytest subprocess and its child processes.
We then compute the average memory (MB) and average CPU utilization (%) over the run.
Let Mgen, Cgen and Mref, Cref denote the corresponding averages for the generated code and the reference implementation.
If the resource suite fails to execute successfully (e.g., failed tests), we set Ru = 0.
Otherwise, we compute reference-aligned ratios and average memory and CPU when both are available:
Ru = min(1, Mref/Mgen) (memory only).
To reflect the fact that non-functional quality attributes correspond to qualitatively different engineering risks (e.g., security vulnerabilities and efficiency regressions), we determine attribute weights using the Analytic Hierarchy Process (AHP). We ground the relative importance ordering on Botchway et al., who apply AHP to expert questionnaires and report maintainability and security as the highest-priority quality attributes, followed by robustness and efficiency. Based on this ordering, we construct a pairwise comparison matrix using the standard Saaty scale. We compute the normalized principal eigenvector to obtain the weight vector and verify consistency using the AHP consistency ratio (CR). In our setting, CR = 0.030 (< 0.1), indicating an acceptable level of consistency. The full AHP derivation (matrix, eigenvector solution, CI/RI/CR) is documented in our anonymous repository for reproducibility.
The non-functional score aggregates five normalized quality dimensions using a weighted sum:
This non-functional score provides a more reliable and discriminative measure of the practical quality of generated applications, beyond functional correctness. In Section 3.2, we show that it is both discriminative across LLMs and stable under reruns.
Evaluation Pipeline
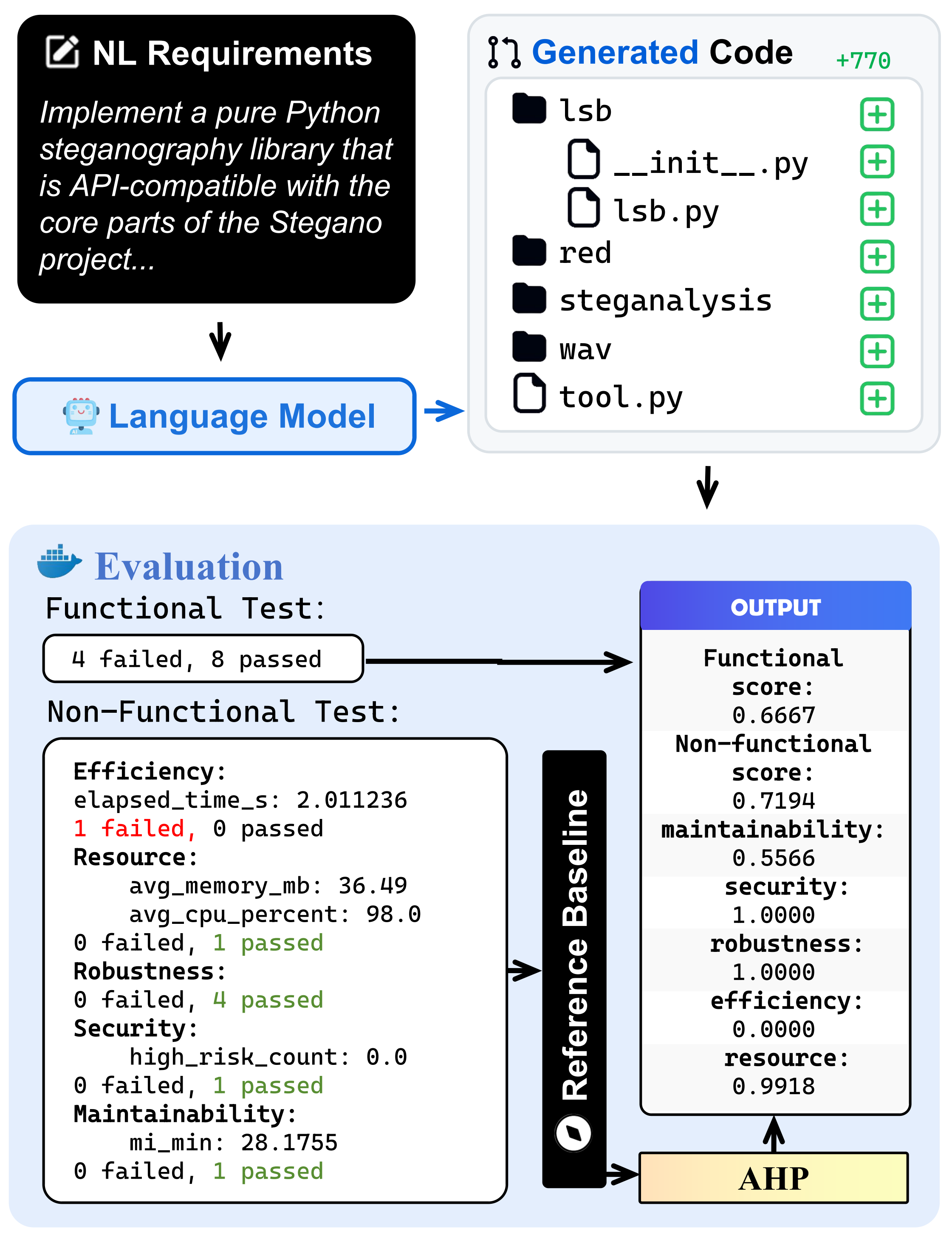
We evaluate application-level code generation with an end-to-end pipeline, as illustrated in the evaluation workflow (Figure 2).
Input. First, for each target project, we provide the LLM with a concise natural-language requirement that captures the core functionality to be implemented. To ensure strict interface alignment and avoid evaluation artifacts caused by mismatched entry points, we also provide the reference repository’s expected module and package surface, guiding the model to generate a repository that conforms to the same API boundary. Given this requirement and the interface constraints, the LLM generates a complete repository from scratch.
Functional Correctness via System Tests. We then evaluate functional correctness using system test suites. Specifically, we execute functional tests against the generated repository and compute the functional score as the pass ratio across all functional test cases, which directly measures whether the generated application behavior matches the reference implementation’s intended functionality.
The Role of Interface Constraints. On Stegano with GPT-5.2, omitting the interface specification yields a functional score of 0.1667. Providing the interface specification increases the score to 0.6667. Inspecting the corresponding failure cases shows that this improvement primarily stems from alleviating test-interface mismatches (e.g., incorrect entry points or module paths) rather than from failing to satisfy the task requirements. As a result, the evaluation more accurately reflects the LLM’s ability to produce an executable repository that satisfies the end-to-end functional requirements.
Non-functional Measurement. Beyond functional correctness, we further assess non-functional quality attributes by running a set of tests and analyses that produce measurable signals used by our scoring functions. These include execution time for efficiency (e.g., elapsed_time_s), resource utilization statistics (e.g., avg_memory_mb and avg_cpu_percent), static security findings (e.g., the number of high-risk issues high_risk_count), and maintainability indicators (e.g., the minimum maintainability index mi_min). For robustness, we define it as the system’s ability to remain stable under stress and edge-case execution paths. We quantify robustness using the pass ratio on our robustness-oriented test suite. A higher score indicates the generated project remains stable under stress and edge-case execution paths.
Reference-normalized Scoring. Because different projects have very different scales, we compute a per-project baseline by running the non-functional suite on the reference repository. We then score each generated repository by comparing its non-functional metrics against this baseline, making results comparable across projects. Concretely, for efficiency, resource usage, security, and maintainability, we first run the same measurement pipeline on the reference repository to obtain a task-specific baseline for each dimension. We then evaluate the generated repository under the same environment and normalize each raw measurement against its baseline using fixed, dimension-specific rules, yielding a score in [0, 1]. A higher score indicates closer-to-reference (or better-than-reference) behavior on that dimension. The exact scoring rules and normalization functions are defined in Section 2.3.
Aggregation and Outputs. Finally, we aggregate the five non-functional dimension scores into an overall non-functional index using an AHP-derived weight vector. This produces a weighted assessment of non-functional quality attributes that emphasizes practically important attributes while remaining consistent across projects. The pipeline outputs both the functional score and the non-functional score, together with the per-dimension breakdown (maintainability, security, robustness, efficiency, and resource usage), enabling the subsequent analyses to localize bottlenecks.
Leaderboard
| # | Model | Func. | Non-func. | Maint. | Sec. | Robust. | Eff. | Res. |
|---|
Citation
If you use RAL-Bench in your research, please cite:
@article{pan2026ralbench,
title = {Beyond Runnable: Are LLMs Ready for Application-Level Functional Correctness and Non-Functional Quality Attributes?},
author = {Pan, Ruwei and Zhang, Yakun and Liang, Qingyuan and Zhu, Yueheng and Liu, Chao and Zhang, Lu and Zhang, Hongyu},
journal = {arXiv preprint arXiv:XXXX.XXXXX},
year = {2026}
}